About This Project
With the rise of cheap sensors and microcomputers, the proliferation of smart power meters, and the reemergence of many machine learning tools, there is an unprecedented opportunity to understand energy-use in buildings. To process all of this data, we are seeking funds to build a low-cost and low-energy computing cluster. With this computing power, we will work on the next generation of control systems for building energy-use management.Ask the Scientists
Join The DiscussionWhat is the context of this research?
Every commercial and residential building exhibits unique energy-use patterns according to its design, climate, mechanical systems, occupancy patterns, etc. As a result, there is no “one-size-fits-all” solution to building energy management. An advanced control system must process sensory data and adapt to the characteristics of a building in real-time.
In short, a building control system must be capable of learning. There is a wealth of machine learning algorithms that are well suited to these kinds of tasks, but figuring out when to use which tool or how to tune it according to the data is a computationally demanding task. To address this, we are researching the use of a parallel computing cluster to simulate and solve these building control questions.
What is the significance of this project?
Building energy use is an ever-evolving field. The adoption of technologies like electric vehicles, internet-connected devices, and renewable energy introduces interesting questions, such as: Should you use power from your solar panels to charge your vehicle or sell it to the grid? Which option saves money and which reduces environmental impact? Can a thermostat estimate and control the temperature in each room? Can a population of refrigerators be used as grid storage, making it easier to integrate renewable energy?
Independently, these questions may have a small impact on the energy use of a single building. However, the additive effect at the grid level has the potential to significantly change the way we use energy and to foster the adoption of renewable technologies.
What are the goals of the project?
Our goals are to build a computing cluster designed for building energy use experiments. Simulating our prediction and control algorithms often involves solving the same problem numerous times under slightly varied conditions. This not only helps us to understand the robustness of the algorithm, but to begin answering questions, such as: How important is forecasting accuracy? How far into the future do we need to predict? Can sensor inputs (like motion and temperature) improve our energy use forecasts?
A computing cluster will be a valuable resource for processing large data sets and for testing new ideas. We will be able to test multiple forecasting algorithms and compare their accuracy in real time. This will go a long way towards increasing the productivity and impact of our research.
Budget
Developing an intelligent control system is an exciting challenge. Currently, one of our largest constraints is access to the computing power needed to process years of data and to simulate the behavior of our control algorithms. Cloud services like AWS are a popular solution to this limitation, but require continuous funding and are less suited to real-time experiments with sensory input. Alternatively, the advent of low-cost microcomputers offers the opportunity to build a high performance parallel computing cluster of our own.
With your support, we will expand our 5 node cluster into a 25 node computing cluster using BeagleBone Black development boards. We will also produce a beginner-friendly, step-by-step guide of how to build the system, enabling other researchers to learn from our experience. This micro computing cluster will help increase the impact of our research.
Meet the Team

As an undergraduate at Swarthmore College, I studied structural engineering before I discovered computer programming, optimal control, and open-source electronics hardware (Arduino). Now, I spend each day figuring out how to combine sensor feeds (like temperature and light intensity) with data streams (like energy-use and weather forecasts) to better understand and control buildings.
Additional Information
Why This Matters:Building energy use is an ever-evolving field. The adoption of technologies like electric vehicles, internet-connected devices, and renewable energy introduces interesting challenges and opportunities. Additionally, every commercial and residential building exhibits unique energy-use patterns according to its design, climate, mechanical systems, occupancy patterns, etc. As a result, there is no “one-size-fits-all” solution to building energy management. An advanced control system must process sensory data and adapt to the characteristics of a building in real-time.
In short, a building control system must be capable of learning. Before we can reduce environmental impacts (by shifting when refrigerators turn on/off or adjusting thermostat settings), we must be capable of predicting how the energy systems in a building will evolve in time. Today, there are a wealth of model identification and machine learning algorithms that can achieve this very goal. However, training, tuning, and testing these algorithms to figure out which one works best for a given task is computationally intensive. Once the algorithms are chosen and the control system programmed, simulating a building's energy use with years of historic data is time consuming. A computing cluster will help us to tackle these challenges and to contribute to reducing the impact of buildings. See Abstract for more.
In More Technical Language:
We are working to develop building energy management algorithms that combine machine learning, model parameter estimation, convex optimization, and model predictive control. In situations where we can confidently model a system (such as temperature in a refrigerator or power output from rooftop PV), we utilize recursive and mini-batch algorithms to estimate the parameters. If a system is stochastic, highly non-linear, or simply difficult to express numerically (such as residential power demand), we use machine learning tools to create models for forecasting. Next, we can define an objective function (such as minimizing cost, energy, CO2 or some combination of each). Finally, we can implement a model predictive control algorithm capable of predicting and managing energy use at discrete time intervals. The ability of the model predictive controller to achieve its objective is highly sensitive to the accuracy and the time horizon of the forecasts.
Determining the optimal inputs, hyperparameter values, forecast horizon, etc. requires extensive sensitivity analysis, a task that a computing cluster is well suited to tackle. We are also working on algorithms for grid-level optimization of energy systems (such as populations of thermal loads or EVs) using distributed optimization and will benefit from the parallel computing capabilities of a cluster. Lastly, we want to validate our control algorithms with real time hardware and software in the loop experiments (for example, controlling the temperature in 100 fridges where 98 devices are being simulated and 2 are being controlled in our lab).
Proof of Concept:
Below is an image of our current 5 node computing cluster (1 manager node and 4 worker nodes). Each micro computer is running an Ubuntu installation and communicating over Ethernet using MPI. This enables each worker node to be given a task by the manager node and to return the solution.

Research Example:
Below is a simple example of our research. The animation shows the results of a residential power demand forecaster using a Support Vector Machine algorithm. To use the forecaster, we first train it by feeding in historic power demand data that has been broken into inputs (the past 6 hours) and outputs (the next 6 hours) for each hour in the data set. Once that is done, we test the forecaster by feeding it data it has not seen before (blue line) and checking how well it predicts the future power demand (red lines).
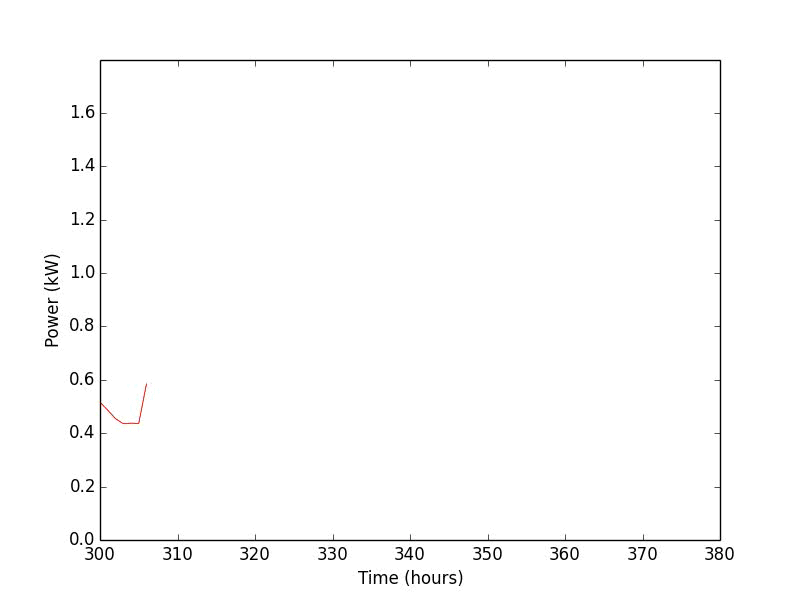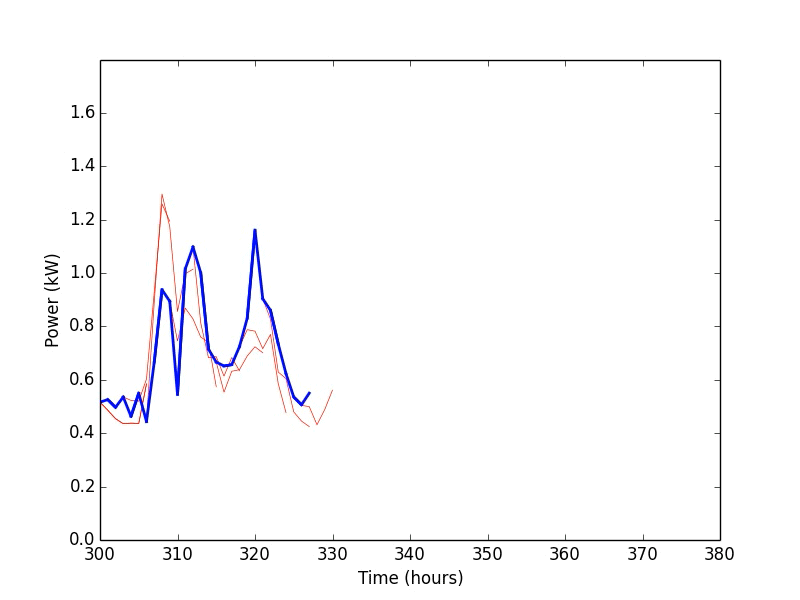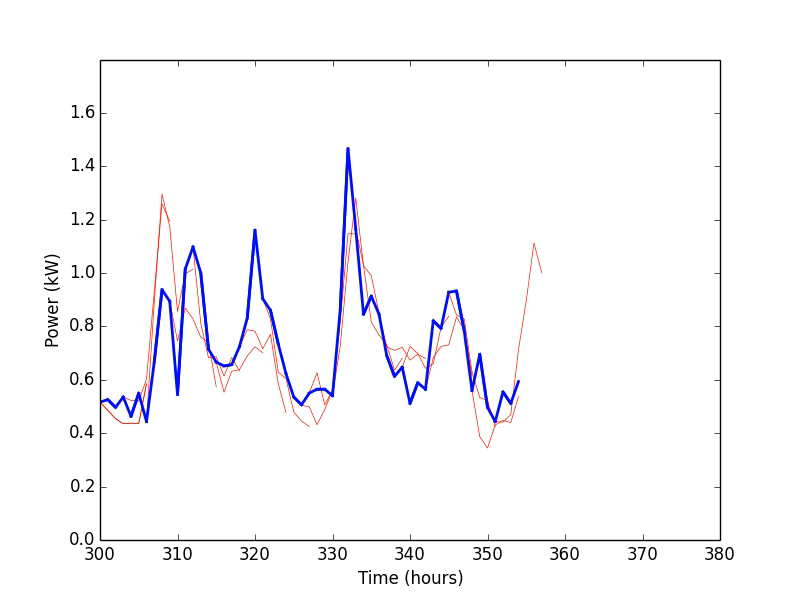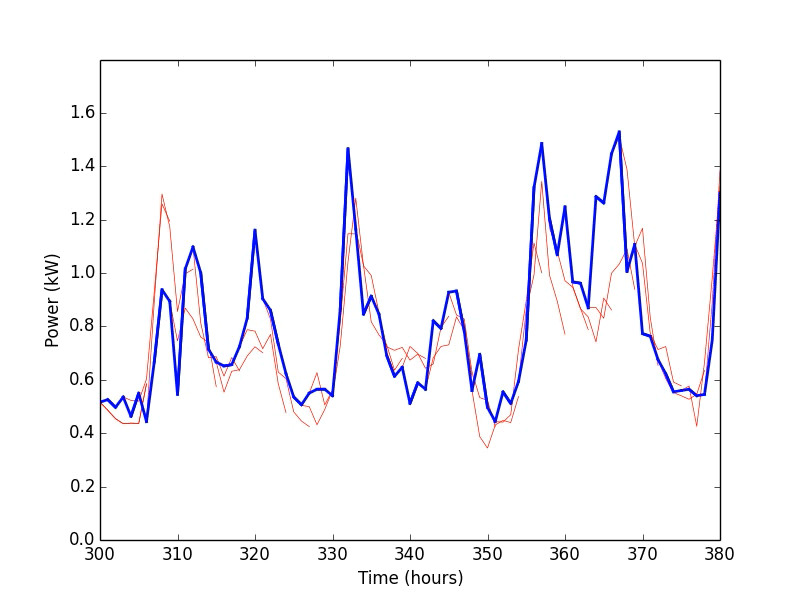
Once that is working, the next question becomes: How does the accuracy of the forecaster change if we adjust the number of hours in the input or output data? To answer this, we will rerun the forecasting experiment 100 times with different lengths of input and output data. In the figure below, the vertical axis is the number of hours in the output data and the horizontal axis is the number of hours in the input data. The color and the radius of the circles correspond to the error (RMSE) of the forecaster for the given input/output lengths. Not too surprisingly, the forecaster is most accurate if we use 24 hours of data as input and a 1 hour forecast as output.
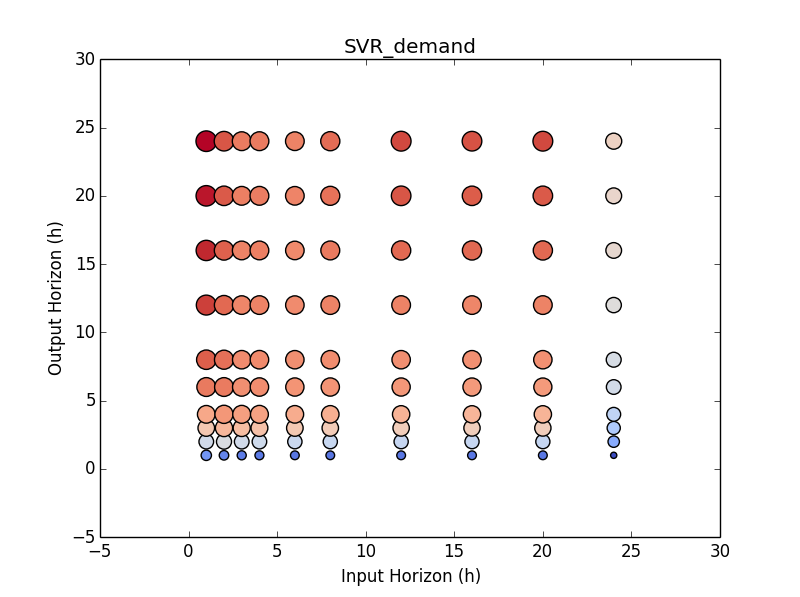
Once we are able to predict the power demand, we can begin to ask questions like: How accurate does the forecaster need to be? How far into the future do we need to predict? How would the results compare if we repeated this experiment with dozens of different algorithms on hundreds or thousands of different buildings? How would exogenous signals like temperature, occupancy, and time of day improve the forecaster? These are just a few of the questions that arise with forecasting power demand.
The potential impact of this work becomes much greater when we begin to think about things like residential solar panels, electric vehicles, building occupancy sensing, and heating/cooling demand forecasting. At eCAL, we are working to understand how we can leverage data streams to improve the performance and reduce the environmental impact of buildings.
Project Backers
- 34Backers
- 104%Funded
- $2,505Total Donations
- $73.68Average Donation